MLLMBench
A Complicated and Comprehensive Multi-modal Large Language Models Benchmark
(2023)
MLLMBench is a complicated and comprehensive benchmarking suite inspired by the multifaceted nature of the vicuna and the revised Bloom's Taxonomy. It encompasses 420 complicated image-instruction pairs across six levels of capabilities: Perception, Understanding, Applying, Analyzing, Evaluating, and Creation, testing up to 42 capabilities of MLLMs. It delves into detailed, real-world scenarios designed to probe the models' abilities in nuanced and complex contexts. You can view and download our dataset on GitHub. We offer a FREE online evaluation platform using GPT-4V-as-a-judge here.
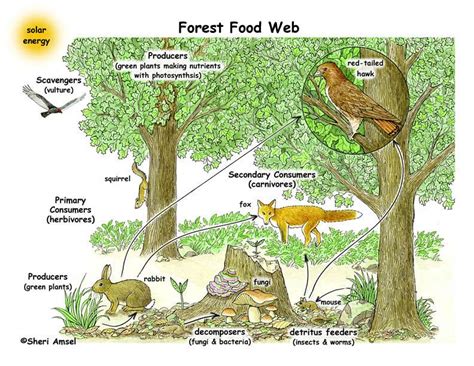
Instruction: Map out the complex interdependencies between species in this food web
and identify any potential cascade effects if one species were to become extinct.
Capability: Natural Relation Understanding
Level: Analyzing
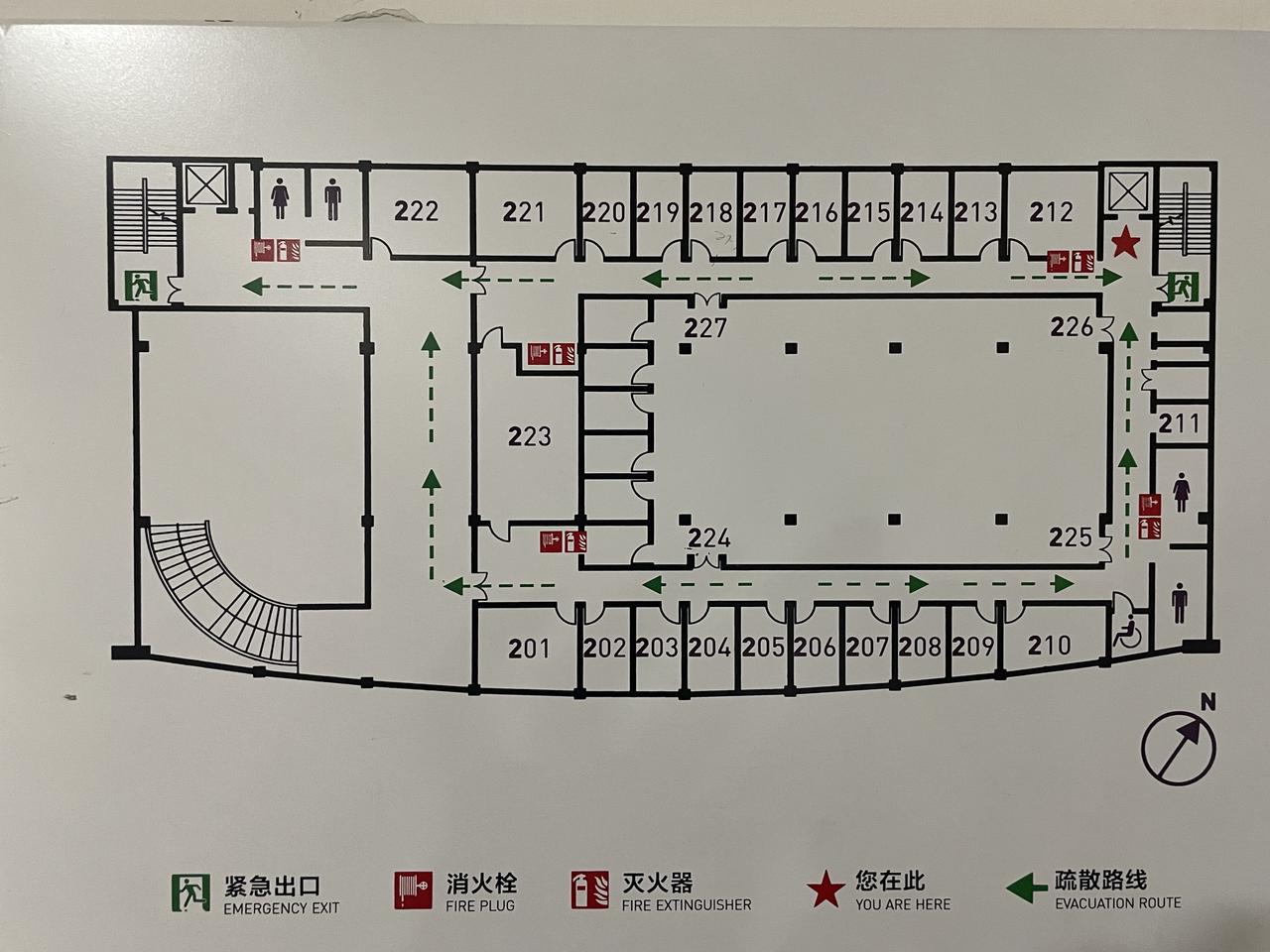
Instruction: Describe the quickest route to the nearest emergency exit from the
"You Are Here" point.
Capability: Document Understanding
Level: Understanding
Hierarchical Capability Level:
Our data can be directly downloaded from Github. Please refer to our GitHub for instructions on how to access and utilize the data.
@misc{ge2023mllmbench,
title={MLLM-Bench, Evaluating Multi-modal LLMs using GPT-4V},
author={Wentao Ge and Shunian Chen and Guiming Chen and Junying Chen and Zhihong Chen and Shuo Yan and Chenghao Zhu and Ziyue Lin and Wenya Xie and Xidong Wang and Anningzhe Gao and Zhiyi Zhang and Jianquan Li and Xiang Wan and Benyou Wang},
year={2023},
eprint={2311.13951},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
For inquiries regarding MLLMBench, please contact us at mllmbench@163.com or create an issue on Github. If you are interested in potential collaboration, please reach out to wangbenyou@cuhk.edu.cn.